

Indeed you are at the right place 💖
I assume you already know about the key concepts of DLTs before you start reading this blog. If this is the case, let’s know more about Hyperledger Fabric.
What is Hyperledger Fabric and does it suits your use-case or application?
Hyperledger Fabric is a private and permissioned 🔐 DLT or a Blockchain to be precise, which comes under the umbrella of Linux Foundation.
As it is permissioned, one can not join or leave the network at any time. The members 👨 of a Hyperledger Fabric network enrol through a trusted Membership Service Provider (MSP), which we will discuss later.
The reason why it gains a mass adoption in Blockchain Marketplace is its modularity & flexibility. It allows to plug in different consensus algorithms, different database to save the data in ledger, and even allow to use different MSP to enrol users.
Hence, if you are looking for a Modular Permissioned-Blockchain Enterprise solution, Fabric can be the choice which you will definitely like.
Architectural Components of Fabric:
Like any permissioned blockchain network, Hyperledger Fabric has various actors & components like orders, peers, client applications, MSPs, CAs, etc. Let’s discuss them one by one.
1. Membership Service Provider:
Any of the actor 👨 in Fabric has an identity & according to the identity, the exact permissions and role of the actor are decided. So, from where do these identities come from and who decide the permissions? Yes, the MSP is the entity that defines rules, permissions and roles of different actors, whose identities have been issued by a valid CA(Certificate Authority).
The documentation says:
MSPs turn verifiable identities issued by CAs into the members of a blockchain network.
Summing up, an MSP abstracts away the protocols behind issuing certificates, validating certificates, and user authentication with all the cryptographic mechanisms, handled by CAs.
Note: Fabric comes with a built-in CA component, called Fabric-CA to allow you to create CA on the blockchain network. However, this component is pluggable and you still have to options to choose from other available CAs.
2. Peers
A peer is a node that hosts instances of the ledger and chaincode in the blockchain network. So, if an application or an admin wants to query the ledger or update the ledger then a connection with a peer is required.
A peer in the fabric network can hold more than one ledgers, which can be governed by one or more chaincodes.
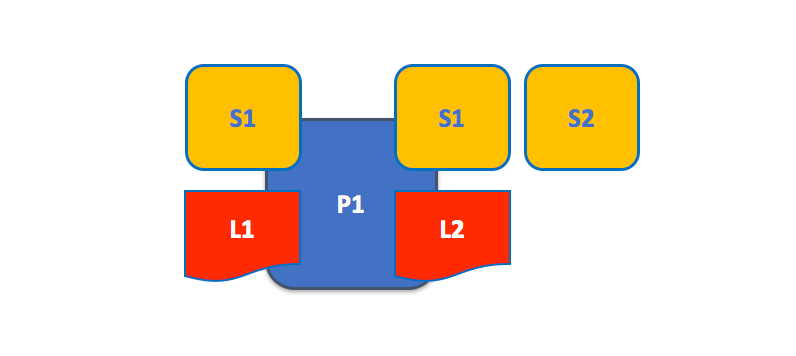
A peer hosting multiple ledgers. Peers host one or more ledgers, and each ledger has zero or more chaincodes that apply to them. In this example, we can see that the peer P1 hosts ledgers L1 and L2. Ledger L1 is accessed using chaincode S1. Ledger L2 on the other hand can be accessed using chaincodes S1 and S2.
3. Orderer
An orderer node packages the transactions into a block 📦, which is then sent to peers, and after verification ✔️ appended to the ledger.
In a fabric network, there are various provisions for the configuration of orderer nodes. We can use a single orderer node (SOLO, deprecated from v2.0) or also a group of orderer nodes can be used to order the transaction and form a block, and this forms an ordering service.
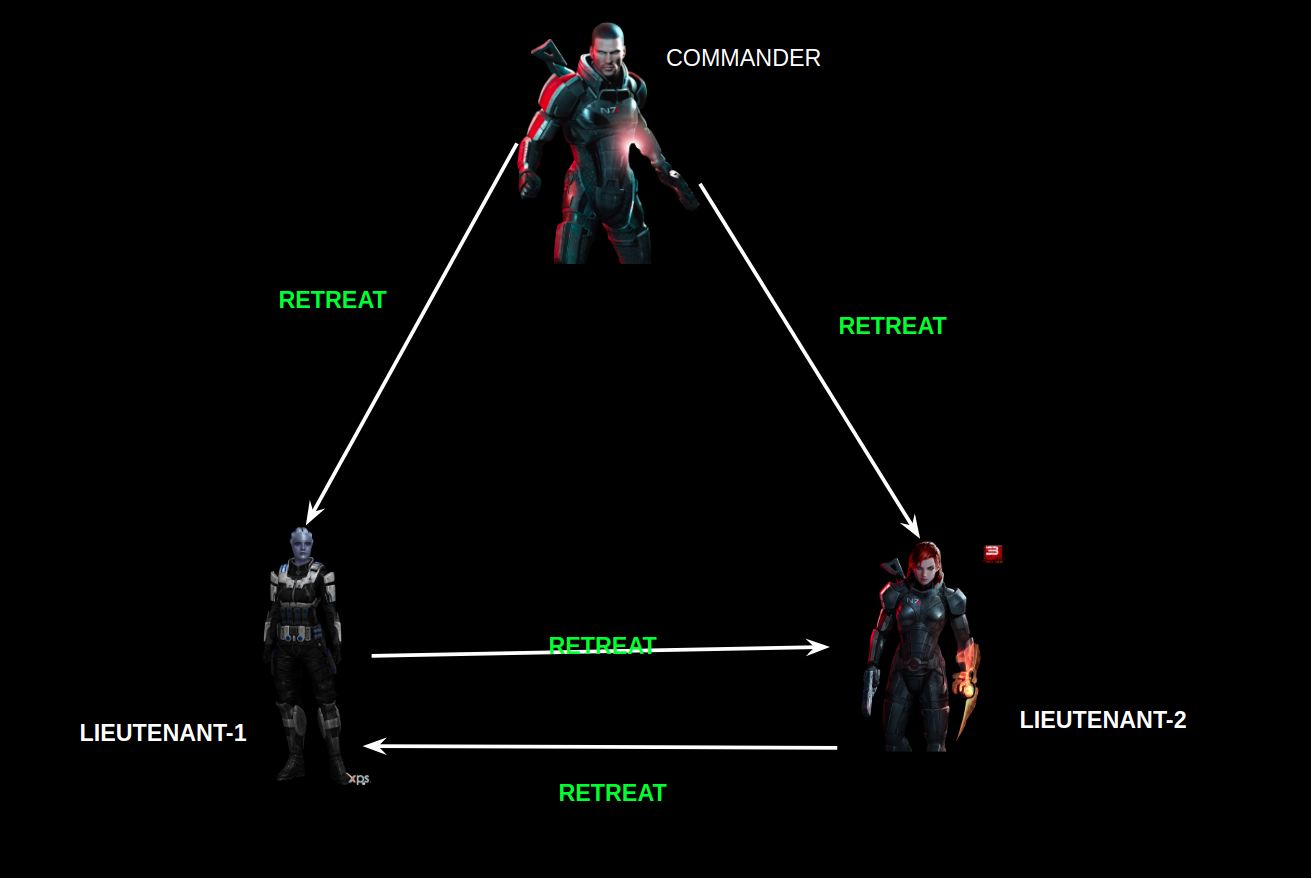
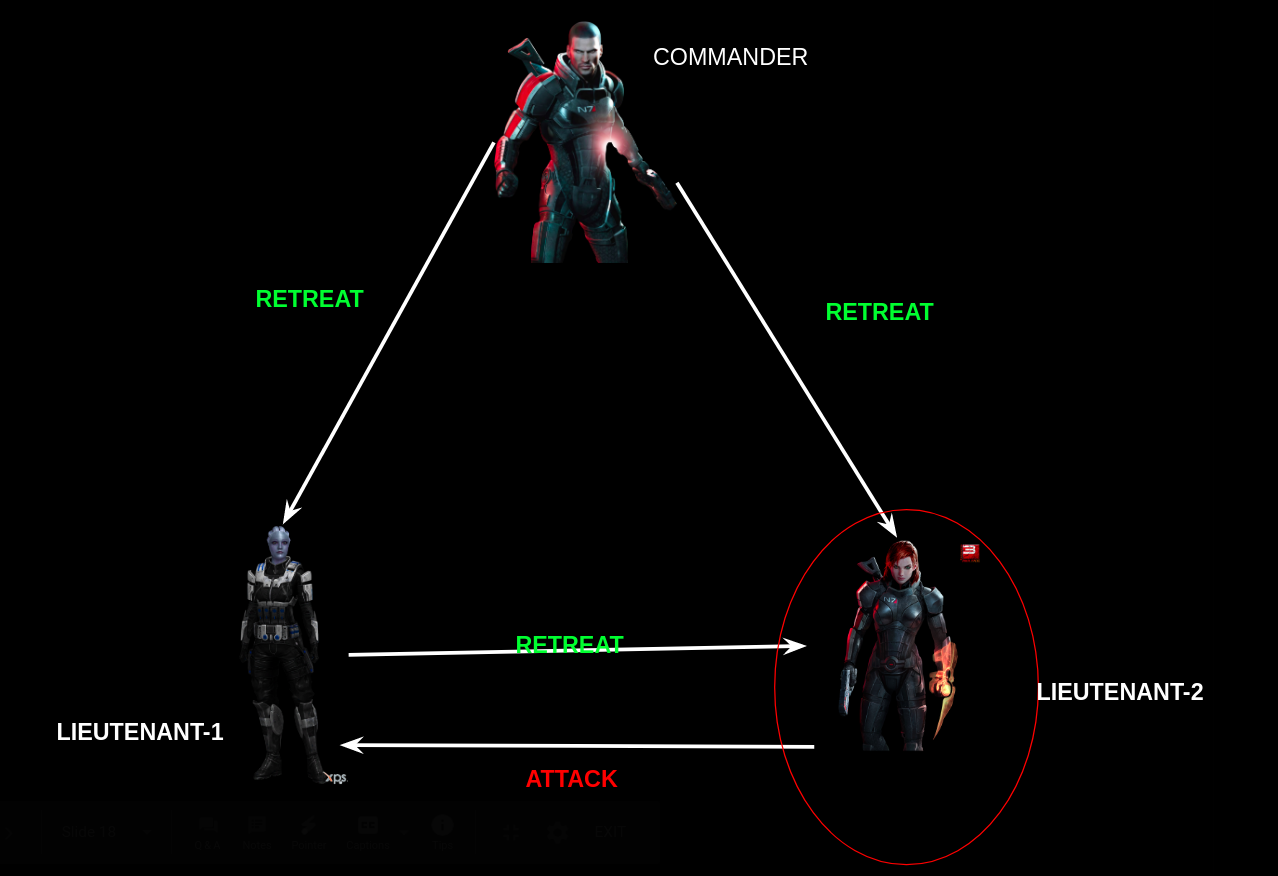
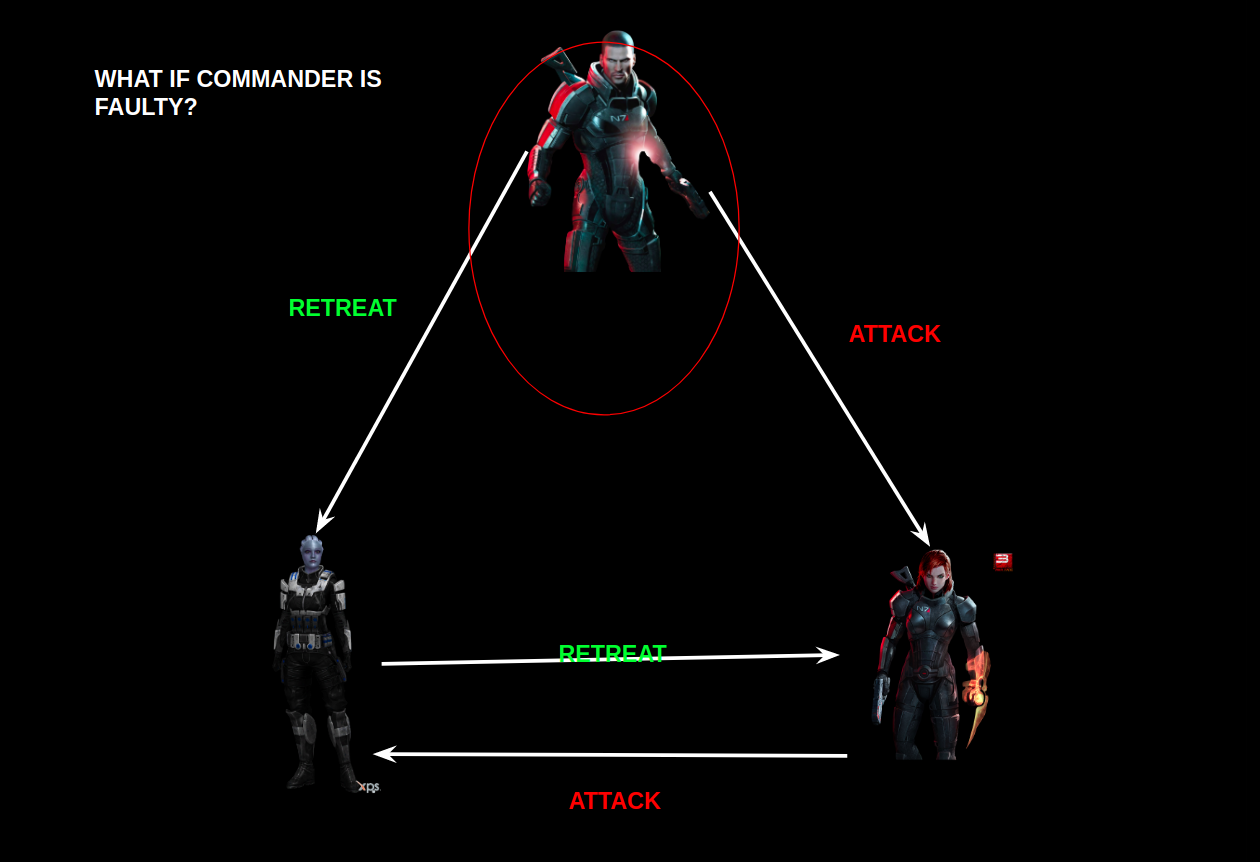
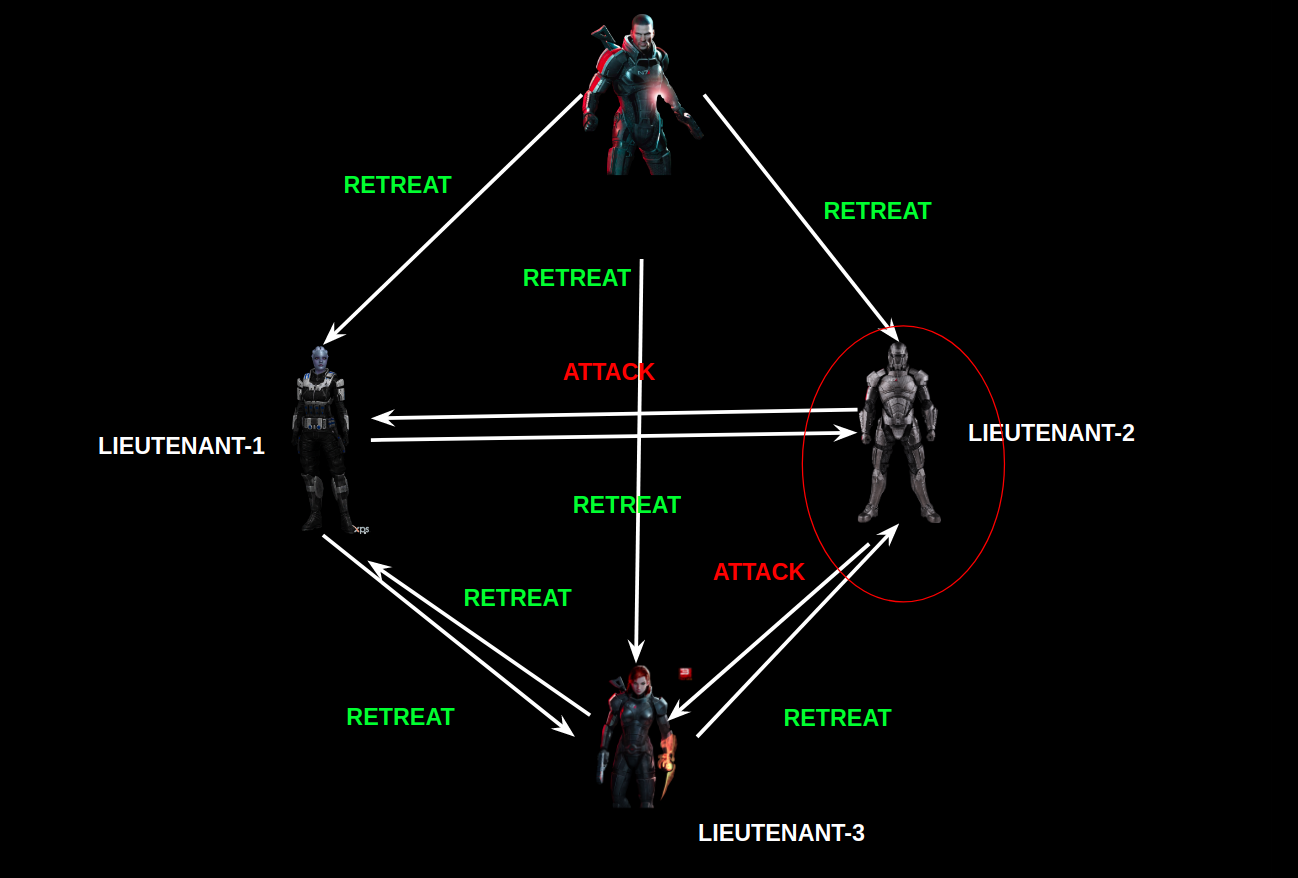
As Fabric is a permissioned blockchain, and real message passing can take place between the nodes, so it doesn’t depend on probabilistic consensus algorithm for ordering of transactions like in the case of Bitcoin and Ethereum. So, all you have to do is to use the consensus algorithm provided by fabric, or you can plug in your own implementation.
4. Channel
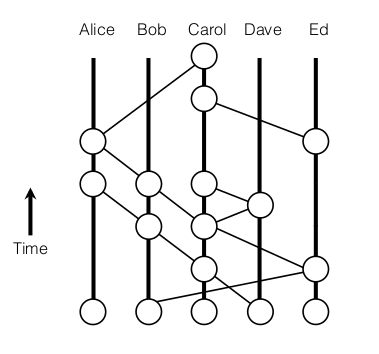
Channel provides a mechanism for the peer to communicate & transact privately. Conceptually, each of the ledger in the network is associated with a channel and the peers which have joined the channel can view and transact on that ledger only.
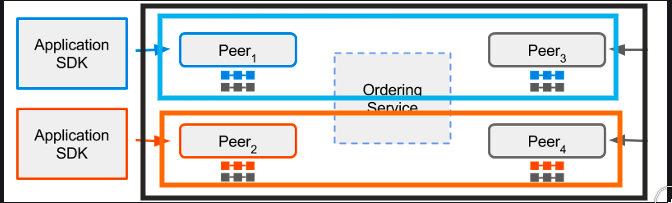
In the above case, three channels C1, C2 &C3 exists, conceptually shown by black, blue, & orange rectangle. Peer P1 & P3 have joined blue channel(C2) and black channel(C1) and P2 & P4 have joined the orange channel(C3) and black channel(C1). So, the Blue ledger is maintained by P1 and P3, whereas Orange Ledger is maintained by P2 and P4, but black ledger is maintained by P1, P2, P3 and P4.
Here is another reference from Fabric’s Documentation:
P1 & P2 have joined channel C1 and thus can access the ledger L1. P2 & P3 have joined channel C2, thus can access ledger L2. The interesting part is peer P2 have joined both the channels, thus can access both the ledgers.
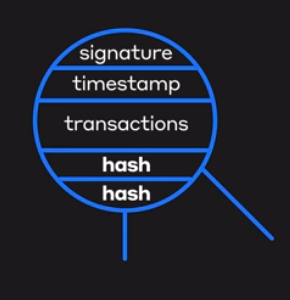
5. Ledger
Fabric’s Ledger 📒 is a distributed database with two components –
World State — the state of the ledger at a given point in time. So, world state stores the most recent value of assets in the form of key-value pairs.
Transaction Log — records all transactions which have resulted in the current value of the world state; it’s the update history for the world state.
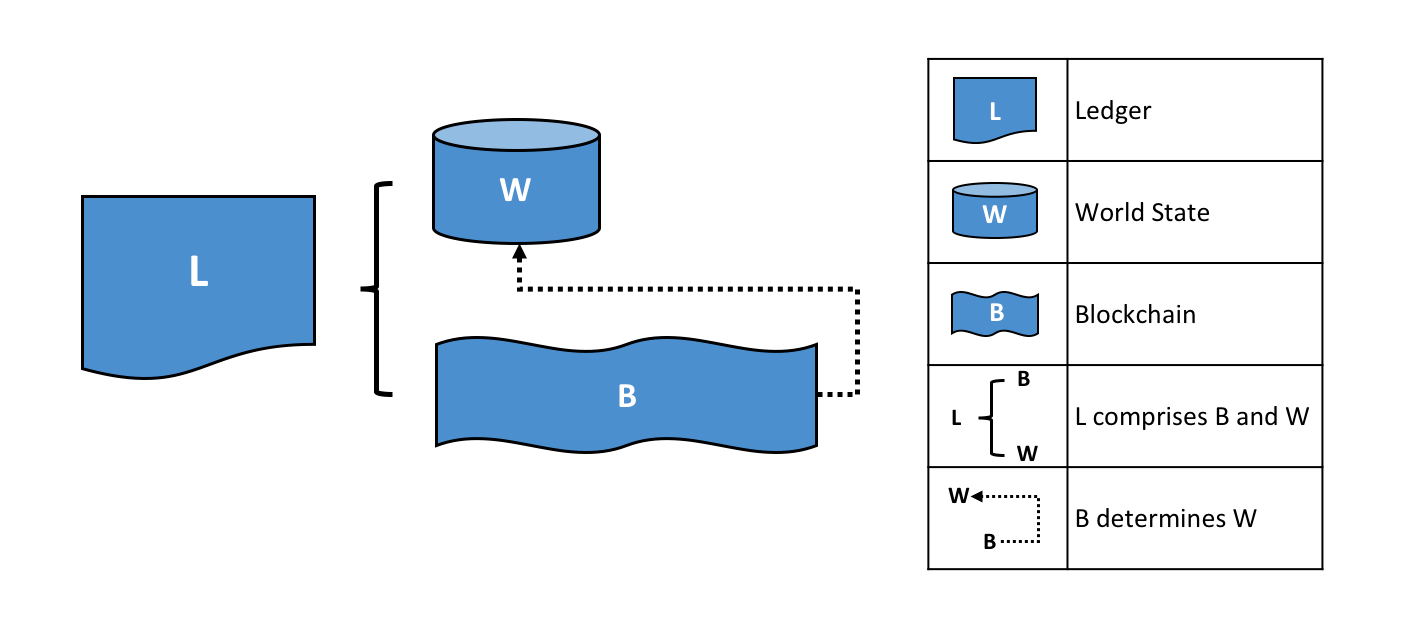
A Ledger L comprises blockchain B and world state W, where blockchain B determines world state W. We can also say that world state W is derived from blockchain B.
A Simple Transaction:
Whenever a transaction is performed, it modifies the world state and the record of the transaction is made in the log of the ledger.
Note:
- In Fabric, the database associated with the world state is pluggable and comes with two choices LevelDB & CouchDB.
- Transaction log doesn’t need to be pluggable.
6.Smart Contract & Chaincode
Smart Contracts are the codes that contain the business logic in the fabric-network. It defines the business cycle of an asset in the world state. So the business logic inside the smart contracts governs all the transactions.
Here is a pseudo-code smart contract from the documentation:

Smart Contracts are packaged into the Chaincode for deployment on the blockchain-network.
Think of smart contracts as governing transactions, whereas chaincode governs how smart contracts are packaged for deployment.
There are also some chaincodes which work on lower-level, to perform the necessary tasks in the blockchain-network, and they are called system chaincodes.
It is better to cover the chaincodes & transaction life-cycle in a different blog, later on 😺.

So that’s it. Thanks for reading.
Official Docs: https://hyperledger-fabric.readthedocs.io/en/release-2.1/
If you are facing difficulties in setting up Hyperledger Fabric, refer:























![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/thumb-1920-430944.jpg)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://media.giphy.com/media/3OqqNQtYNc52lI17PT/source.gif)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/a.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/b.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/c.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/d.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/e.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/f.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/g.png)
![GIT and GITHUB: A Layman’s Guide [Part-2]](https://cevgroup.org/wp-content/uploads/2019/05/download-2.jpeg)
![GIT and GITHUB: A Layman’s Guide[Part-1]](https://cevgroup.org/wp-content/uploads/2019/05/git-github.jpg)
![GIT and GITHUB: A Layman's Guide[Part-1]](https://cevgroup.org/wp-content/uploads/2019/05/yancy-min-1536531-unsplash.jpg)
![GIT and GITHUB: A Layman's Guide[Part-1]](https://cevgroup.org/wp-content/uploads/2019/05/18333fig0106-tn.png)
![GIT and GITHUB: A Layman's Guide[Part-1]](https://cevgroup.org/wp-content/uploads/2019/05/imageedit_5_5145749285.gif)
![GIT and GITHUB: A Layman's Guide[Part-1]](https://cevgroup.org/wp-content/uploads/2019/05/imageedit_7_2123867962.gif)















js.jpeg?width=259&name=ethers(dot)js.jpeg "ethers(dot)js")



















